Linux勉強会レポート Vol.1

1.今回のテーマと内容
今回のテーマは、「サーバーとは何か?」「サーバーに求められるもの」「高可用性技術」「サイジングの基礎」です。このように書くと、「えっ? Linux基礎勉強会なのに?」と思われる方もいると思います。しかし、「サーバーとはどういうものか? どうあるべきか?」。普段から「サーバー」に触れており、かつ、聞き慣れてはいるものの、いざそんな問いかけをしてみると、殆どの受講生は「えっ・・?」と首を傾げ、戸惑いの表情を浮かべておりました。今更な内容かもしれませんが、「Linuxを学ぶ上でサーバーとはどういうものか? どうあるべきか? を知ることは非常に大切です」。そんな講師のコメントに「よしっ!一から頑張ってみよう!」。そんな表情を受講生は浮かべておりました。
では、今回はコンテンツをご紹介します。 皆さん「Linuxを学ぶ上で、サーバーの知識の土台は欠かすことができません!」。しっかりと学びましょう。
1.1 サーバーとは何か?
「『サーバー』とは、クライアントからの要求に対してサービスを提供するコンピューター。『クライアント』とは、サーバーに対してサービスの依頼を行いその提供を受けるコンピューターのこと。つまり、サーバーからサービスを受ける」から講義は始まりました。
すると多くの受講生は「なんだ! そんなことは当たり前じゃないか」という表情を浮かべます。
その表情を見つめつつ講師は立て続けにこのように切り出します。「では皆さんの日常でどのような使われ方をしてますか?」。その問いを発した瞬間、言葉に詰まる受講生・・。そこで「ネットワークの構成」と絡めながら以下のように説明を続けます。
①ピア・トゥ・ピア型ネットワーク (テキストより抜粋)
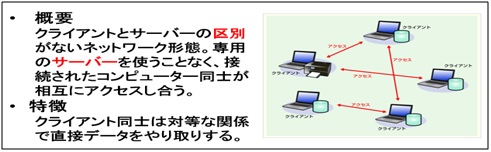
②クライアント・サーバー型ネットワーク (テキストより抜粋)

サーバーに携わるうえで、「どのような構成になっていて、どのような使われ方をしているのか? どのような役割を担っているのか? サーバーに関わるうえで大切だから、今回の講座を通じてしっかり学びましょう!」。そのように講師は熱く語りながら、「ファイル共有、共有プリンタ」等、日常業務での利用ケースをサンプルにして、サーバーとクライアントの役割について説明を進めました。
受講生も「あっ! そういうことなのか!」という納得の表情を浮かべておりました。
1.2 サーバーに求められるもの
続けて講師はこのような問いを受講生に投げかけます。「サーバーとは何かはわかったと思います。ではサーバーに求められるものとは何でしょう? サーバーとはどうあるべきでしょうか?」。 するとある受講生から「動き続けること」という答えが返ってきます。講師は微笑みながら、「そう、その通り! 24時間365日サービスを提供し続けられることですね。」 と受講生に説明をします。「24時間365日サービスを提供し続けることを目指すために、エンジニアとして知っておくべきサーバー稼働に関する指標」というのがあるのですが、いったいどのようなものでしょうか? これをこのセクションで学びましょう。
最初に講師は「サーバーの稼働に関する指標値」として、以下の各項目について、例を交えながら説明を始めます。
①平均故障間隔(MTBF)
②平均故障時間(MTTF)
③平均修理時間(MTTR)
④稼働率(%)
①平均故障間隔(MTBF)
故障と故障の間の時間 = 稼働している時間。

稼働している時間を合計して割り算すると平均故障間隔を出すことが出来る。
(600 + 200 + 400) ÷ 3 = 400
この場合 400時間が、平均故障間隔となる。値が大きければ大きいほど「故障しにくく信頼性が高い」
②平均故障時間(MTTF)
機器の寿命がどれくらいかを示す指標

一回故障すると、それで使えなくなるという場合に使われる。
例えば、ハードディスクやSSDなどのストレージの交換期間の目安となる。
「MTTFが5年」とは「平均5年の稼働時間で故障する」という意味。
③平均修理時間(MTTR)
故障から復旧(修理完了)までの時間。

復旧中の時間を合計して割り算をすると平均修理時間を割り出すことができる。
(1h + 3h + 2h) ÷3 = 2h
この場合、2時間が平均修理時間となる。値が小さければ小さいほど「復旧にかかる時間は短い」
④稼働率(%)
故障から復旧(修理完了)までの時間。

稼働率は、MTBF÷(MTBF + MTTR)×100% で算出する事ができる。
MTBF = (600 + 200 + 400)÷ 3 = 400
MTTR = (1 + 3 + 2)÷ 3 = 2
400 ÷(400 + 2)× 100 = 約99.5%
今回の例では、本サーバーの稼働率は約99.5%となる。値が大きければ大きいほど「稼働率は高い」。
言葉としては聴いたことはあっても、「どういう時に使うか?」を知らない受講生が殆どのようで、「へー」という表情の受講生。続けざまに講師はここまでで説明をしたサーバーの指標値を使い、「コンピューターシステムに求められるものを評価する指標=RASIS(ラシス・レイシス)」についての説明へと講義を進めていきます。
①Reliability(信頼性)
故障しにくい事。一般的に「平均故障間隔(MTBF)」で評価。値が大きいほど信頼性高
②Availability(可用性)
高い稼働率を維持できる事。一般的に「稼働率(%)」で評価。値が大きいほど可用性高(高可用性)
③Serviceability(保守性)
障害復旧やメンテナンスのしやすさを。一般的に「平均修理時間(MTTR)」で評価。値が小さいほど保守性高
④Integrity(保全性)
データに矛盾がなく一貫性を保っている事
⑤Security(安全性)
機密性が高く、不正アクセスがされにくい事
特に最初の3つ(Reliability、Availability、Serviceability = RAS)が重視されること。さらに「Serviceability(保守性)」を深く掘り下げて、「RTO(目標復旧時間)、RPO(目標復旧時点)、RLO(目標復旧レベル)、MDPD(最大許容停止時間)」について解説を進めました。 横文字の用語が数多く登場し、「説明を聞き漏らすまい!」と必死にノートを取りながらも、「たくさんあって覚えるの大変・・」という表情を浮かべておりました。
ある受講生からは「普段設計書を書く上でこれらの用語は何度か見たことあったけど、細かい意味は今まで知らなかった。そういうことだったのですね!」という新たな発見をした喜びのコメントもあり、講師もうれしそうな表情を浮かべるのでした。
1.3 高可用性を実現する技術
まだまだ講義は続きます! RASISの説明の中で登場した「高可用性」を実現するための技術の説明に入ります。
高可用性を学ぶ上で欠かせないうえで必要な考え方に「冗長化」があります。これらに関わる以下の各項目について、例を交えながら説明を始めます。
「冗長化」という言葉自体を聞いたことあるものの、「具体的にどのように実現するか?」について、体系的に知らない受講生が殆どで、講師の説明に耳を傾け、講義内容に聞き漏らすまいとノートを必死に撮り、そして講師からの指名に対しても、自分で取ったノートを見ながらも、何とか回答をしようとする熱意ある受講生態度がとても印象的でした。
講師側もこの項目が、今回の講義の「肝」であることは百戦錬磨の経験からも十分理解しているためか、説明にも更に熱が入っておりました!
①冗長化とは?
②冗長化の方法
③ハードウェアを複数で構成させる技術
④複数のサーバー(機器)で構成させる技術
⑤アクティブ⇔スタンバイの冗長化方式
⑥アクティブ⇔アクティブの冗長化方式
①冗長化とは?
システムに何らかの障害が発生した場合に備えて、 障害発生後でもシステム全体の機能を維持し続けられるよう
に、予備機を平常時からバックアップ機として配置し運用しておくこと。
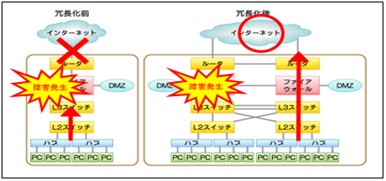
②冗長化の方法
主に以下の方式で冗長化を実現する。
1) サーバー内のHWを複数で構成 →ハードディスクのRAID、NICのチーミング
2) 複数のサーバー(機器)で構成 →稼働系機器と待機系機器で運用
3) システムを遠隔地に構築 →災害対策環境、遠隔地バックアップなど
③ハードウェアを複数で構成させる技術
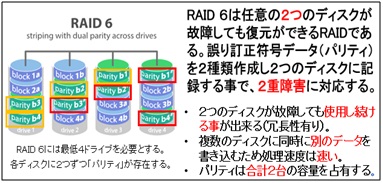
本講座ではRAIDの技術について重点的に解説。RAIDには0から6までの7種類。その中で
よく利用されるものとして「RAID0・1・5・6」がある。
RAIDコントローラーやソフトウェアによって使用できるRAIDのレベルが規定されるケースが多い。
④複数のサーバー(機器)で構成させる技術
障害発生時に本番システムから予備システムへ切り替える方式。代表的なものとして以下がある。
1) アクティブ ⇔ スタンバイの構成
・ ホットスタンバイ
予備サーバーも起動状態にして、本番サーバーと同じサービスやアプリケーションを起動し、
同時に処理を実行しながらデータをリアルタイムで同期し続ける方式。
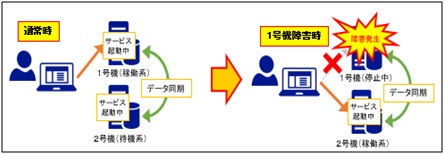
・コールドスタンバイ
予備サーバーを、通常は使用しない状態にしておく方式。 設計や運用により、 通常時は電源停止など
完全に停止させている場合もある。
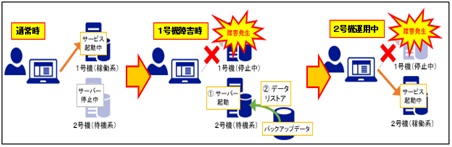
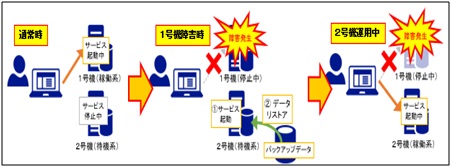
・ウォームスタンバイ
予備サーバーは、機器本体やOSなどは起動するが本番系と処理やデータの同期などは行わず、
切り離された状態で待機させる方式。
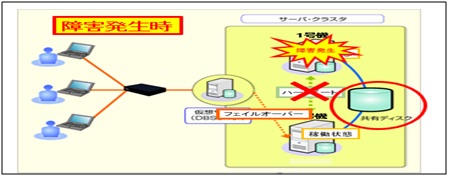
・サーバクラスタリング
冗長化のため、複数サーバーを用意するが、クライアント側からは1台の仮想サーバーとして認識させて、
アクセスさせる。障害が発生した場合も、いずれかのサーバーが稼働していれば、クライアントにサービスを
提供できる高可用性のための技術。
2) アクティブ ⇔ アクティブの構成
・負荷分散方式
冗長化のため、複数のサーバーを用意するが、クライアント側からは1台の仮想サーバーとして認識させて、
アクセスさせる。障害が発生した場合も、いずれかのサーバーが稼働していれば、クライアントにサービスが
提供できる高可用性のための技術。
クラスタリングとの違いは、接続サーバーが共有ディスクを持たない「アクティブ⇔アクティブ」の構成になる点。
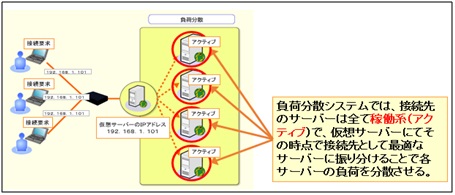
基礎講座とは言え難しい内容。高可用性に関する各々の技術について「特徴・メリット・使用ケース等」重要ポイントを「何とか持ち返ってもらいたい!」という想いからか、一つ一つの説明で図を交えながら、嫌が上にも講師の声は更にトーンが上がります。また「講師側からの受講生を指名回数も」増えました。呼応されるように受講生も必死に食らいつく姿がとても心を打ちました!
1.4 用途によるサイジング
そして第1回目締め括りとして、「サーバーのサイジング」についての説明へ入ります。サーバーは様々なハードウェアから構成されますが、特にその中でも重要な「CPU・HDD・メモリー」について取り上げます。サーバーの設計をする上で、「どのような考え方でサイズを見積もるか?」という考え方は難しく肝ともいえるでしょう。講師も長年の経験で試行錯誤しながら苦労をした記憶があります。もちろんその前に「CPU・HDD・メモリー」とは何かから説明をし、そのあとから本題のサイジングに入ります。
①CPU
Central Processing Unitの略。別名:プロセッサー。 人間の体で例えると頭脳にあたる。
パソコンには必ず搭載されている部品で、マウス、キーボード、ハードディスク、メモリー、周辺機器などから
データを受け取り、 コンピューターでは「制御・演算」を担当する。
②HDD
コンピューターシステムにおける記憶装置の一種で、磁気記憶方式によってデータを読み書きする装置のこと。
③メモリー
コンピューターにおいてプログラムやデータを記憶する装置のこと。
講師はここで一つ質問を投げかけます。「HDDもメモリーも記憶装置ですよね?でも何か違いがあるはずですね。なんだと思いますか?」。質問内容に「すぐにピン!」と来た人も多く、講師の指名に対して「HDDは保存すればデータは残るけど、メモリーだとデータは消えてしまう」という回答します。講師も満足気味に「その通り! サーバーやPC上での作業データを一時的に保存するのがメモリー。だから電源が落ちたりしたら消えてしまう。それを対して電源を止めた後でもデータ残る。これがHDD。皆さんもOffice製品を使っており上書き保存をすると思いますが、あれもデータをHDDに保存するんです。」という日常の作業を例にする講師の説明に、受講生も納得した表情でした。
そして最後にそれぞれのハードウェアのサイジングの考え方についてサンプルを交えて説明を行い、第一回目の講義は終了。第一回目の講義だけでたくさんの内容を学び、受講生も少々疲れ気味ではありましたが、基礎の大切さを痛烈に実感した様子でした。さて以下の答えは何になるでしょうか? それは講座に参加してご自身で答えを出せるようになってくださいね。
①CPUサイジング
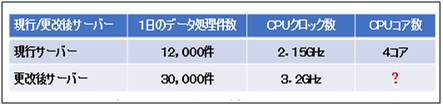
②HDDサイジング

③メモリー

2.次回予告
第2回Linux基礎勉強会は「Linuxの機能と役割」「Linuxの使い方(コマンド基礎操作/ログの見方等)」について重点的に講義します。いわば本勉強会の講座の中でも、特に「要」となる講義になります。
Linuxに関わる立場として欠かすことのできない基礎知識です。しっかりと学びましょう!
3.受講者の声と評価
今回の参加人数15名、辛口の受講者アンケートでは、満足度の平均が「90.6点」でした!
「こういった基礎から学べる機会が現場ではないが業務で必要な知識であったため、学ぶことができて良かった。」
「昔の現場で意味が分からず聞き流していた言葉の意味が改めて分かった」
「知りたいと思っていたサーバーの仕組みや構造について知ることができた」
など、多くの評価を頂きました。
しかしその一方で「ノートを書くのに必死になってしまった」「後半少し説明が駆け足気味だった」等課題も残りました。
「受講生の声を真摯な気持ちで参考にして第2回目以降の勉強会に臨みたい!」と担当講師も決意を新たにしておりました。
4.今回の勉強会で伝えたい事
今回の勉強会での学びを通じて、「とにもかくにも基礎/基本を大切に」して頂きたい!」ということを担当講師は熱く語っておりました。エンジニアとして成長をするためにも「基礎を地道に」学ぶことは大切ですし、講師の経験則からも「基礎を大事にしたからこそ今がある」と申しておりました。
地道な努力は少しずつではありますが、必ず身につきますし、いつか「努力はいつか花が咲き、飛躍的な成長」に繋がります!また「良く分からない…」などと諦めず、くらいついてほしい。わからないことがあったら「いつでも遠慮なく聴いてほしい」。そのようにも語っておりました。受講生の皆さん。本レポートを読まれた方。経験豊富な講師を上手に活用し、基礎を確実に身に付けていきましょう!