
Javaの標準APIでXMLを読み込む方法|4つの読み込み方法をサンプルで比較しよう

XML(Extensive Markup Language)は、プログラムの設定を書いたり、プログラム間でのデータ送信に使うデータフォーマットです。最近はJSONやYAMLに押されてはいますが、それでも幅広く使われていますよね。
プログラムを作る時は、XMLを読む方法を知っていると便利です。多分、XMLを作るよりも読む機会の方がずっと多いでしょうし、XMLを読むのは簡単そうに見えて意外とてこずるものだったりするのです。
もちろんJavaではXMLの読み込みは標準機能としてあります。つまり、JavaをインストールすればXMLを読み込むためのライブラリが一緒に付いてきますので、使い方さえ少し学べば、今すぐにでも使い始められます!!
この記事では、JavaでのXMLの読み込み方を初心者向けにざっとお伝えします。大きく分けて4つのやり方があるのですが、それぞれのサンプルプログラムを通じて、使い方や特徴をご理解いただければと思います。
※この記事のサンプルは、Java 12の環境で動作確認しています

目次
1.Java SEの標準APIにはXMLを読み込む方法が4つある
JavaでXMLを読み込む方法は、Java SE 12の時点では以下の4つが代表的です。この記事では、これらの方法で同じXMLを読み込んでみて、それぞれの方法でプログラミングの仕方がどう違うのかを学んでいきます。
- DOM(Document Object Model、ドム)
- SAX(Simple API for XML Processing、サックス)
- StAX(Streaming API for XML、スタックス)
- XPath(XML Path Language、エックスパス)
なぜXMLを読み込むのに4つも方法があるの?と思われたかもしれません。なぜなら、それぞれのプログラムの作り方には、得意・不得意があるからです。逆に言えば、プログラムの都合に合わせて使い分けができるのです。
この4つ方法には、以下のような特徴があります。この記事のサンプルプログラムを順番にご覧になっていただけると、それらが具体的に分かると思います。
| プログラミングの仕方 | 得意 | 不得意 | |
|---|---|---|---|
| DOM | XMLのツリー構造を前提に読み込んだり検索する | ツリー構造を使った要素の検索と操作 | 構造が入り組んだXMLの読み込み |
| SAX | イベントベース | 必要な要素の情報を簡単に得られる | XMLのツリー構造を意識したプログラミング |
| StAX | イベントベース(SAXとは少し異なる方法) | 必要な要素の情報を簡単に得られる | XMLのツリー構造を意識したプログラミング |
| XPath | 専用の構文で必要な要素を指定する | 読み取りたい要素や属性を一回のクエリで検索できる | XPathだけでは何もできない(DOMの関連クラスの知識が必要) |
1-1.この記事で使うXMLの紹介
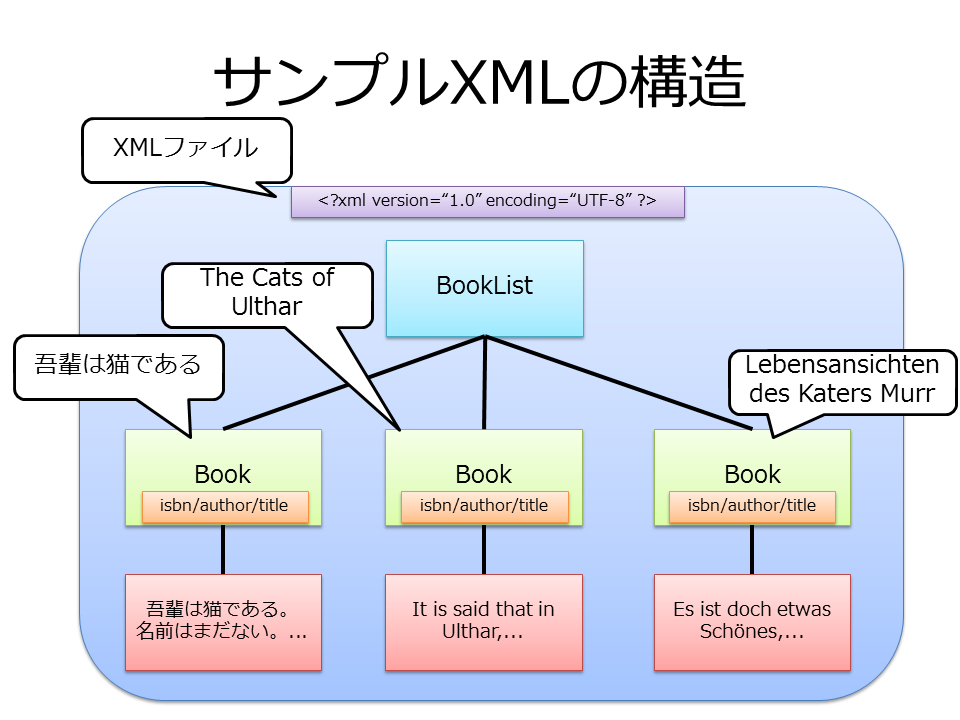
この記事では、以下のXMLを共通して使います。内容は本(Book)の一覧(BookList)です。それぞれの本は、属性としてISBN(isbn)、著者名(author)、タイトル(title)があり、テキストとして本文の書き出しがあります。
<?xml version="1.0" encoding="UTF-8" ?> <BookList> <Book isbn="ISBN978-4-1234-0001-5" author="夏目漱石" title="吾輩は猫である">吾輩は猫である。名前はまだない。どこで生れたかとんと見当がつかぬ。</Book> <Book isbn="ISBN978-4-1234-0002-2" author="H. P. Lovecraft" title="The Cats of Ulthar">It is said that in Ulthar, which lies beyond the river Skai, no man may kill a cat;</Book> <Book isbn="ISBN978-4-1234-0003-9" author="E. T. A. Hoffmann" title="Lebensansichten des Katers Murr">Es ist doch etwas Schönes, Herrliches, Erhabenes um das Leben!</Book> </BookList>
1-2.この記事で目的とする出力内容
この記事では先ほどのXMLを読み込んで、本の情報を以下のように出力するプログラムを、それぞれの方法で作ります。同じXMLから同じことを出力するのですが、かなり違うやり方になりますよ。
isbn = ISBN978-4-1234-0001-5 author = 夏目漱石 title = 吾輩は猫である text = 吾輩は猫である。名前はまだない。どこで生れたかとんと見当がつかぬ。 isbn = ISBN978-4-1234-0002-2 author = H. P. Lovecraft title = The Cats of Ulthar text = It is said that in Ulthar, which lies beyond the river Skai, no man may kill a cat; isbn = ISBN978-4-1234-0003-9 author = E. T. A. Hoffmann title = Lebensansichten des Katers Murr text = Es ist doch etwas Schönes, Herrliches, Erhabenes um das Leben!
2.DOM(Document Object Model)で読み込む
DOM(Document Object Model)は、HTMLなどの規格を作っているW3Cが決めたXMLの操作方法です。Javaに限らず、いろいろなプログラミング言語で共通で使える、XMLの読み込み方法です。
Document Object Model
https://ja.wikipedia.org/wiki/Document_Object_Model
W3C Document Object Model
Document Object Model (DOM) Technical Reports
DOMの特徴は、XMLの「木構造(ツリー構造)」をプログラム上でそのまま扱えることです。XMLはルート要素に子要素がぶら下がるツリー構造を持ちますが、DOMではその構造ありきでプログラムをしていくのです。
2-1.DOMでのXML読み込みプログラム
では、早速DOMを使ったJavaでのXMLの読み込みプログラムを見てみましょう。
import java.nio.file.Paths;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
public class DomSample {
public static void main(String[] args) throws Exception {
// 1. DocumentBuilderFactoryのインスタンスを取得する
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2. DocumentBuilderのインスタンスを取得する
DocumentBuilder builder = factory.newDocumentBuilder();
// 3. DocumentBuilderにXMLを読み込ませ、Documentを作る
Document document = builder.parse(Paths.get("/bookList.xml").toFile());
// 4. Documentから、ルート要素(BookList)を取得する
Element bookList = document.getDocumentElement();
// 5. BookList配下にある、Book要素を取得する
NodeList books = bookList.getElementsByTagName("Book");
// 6. 取得したBook要素でループする
for (int i = 0; i < books.getLength(); i++) {
// 7. Book要素をElementにキャストする
Element book = (Element) books.item(i);
// 8. Book要素の属性値と、テキストノードの値を取得する
String isbn = book.getAttribute("isbn");
String title = book.getAttribute("title");
String author = book.getAttribute("author");
String content = book.getTextContent();
System.out.println("isbn = " + isbn);
System.out.println("author = " + author);
System.out.println("title = " + title);
System.out.println("text = " + content);
System.out.println();
}
}
}2-2.プログラムの簡単な解説
このプログラムは以下のようなことをしています。
- XMLからBookList要素を取得して…(4.)
- BookList要素の下にあるBook要素を全て取得して…(5.)
- それぞれのBook要素から属性とテキストを取得してprint!!(6. 7. 8.)
このプログラムで、サンプルXMLの何がどの変数に入っているのかを図にしました。上から順番に自分の子要素を得ているのがわかるでしょうか。これが、DOMがXMLのツリー構造をベースにしているということです。
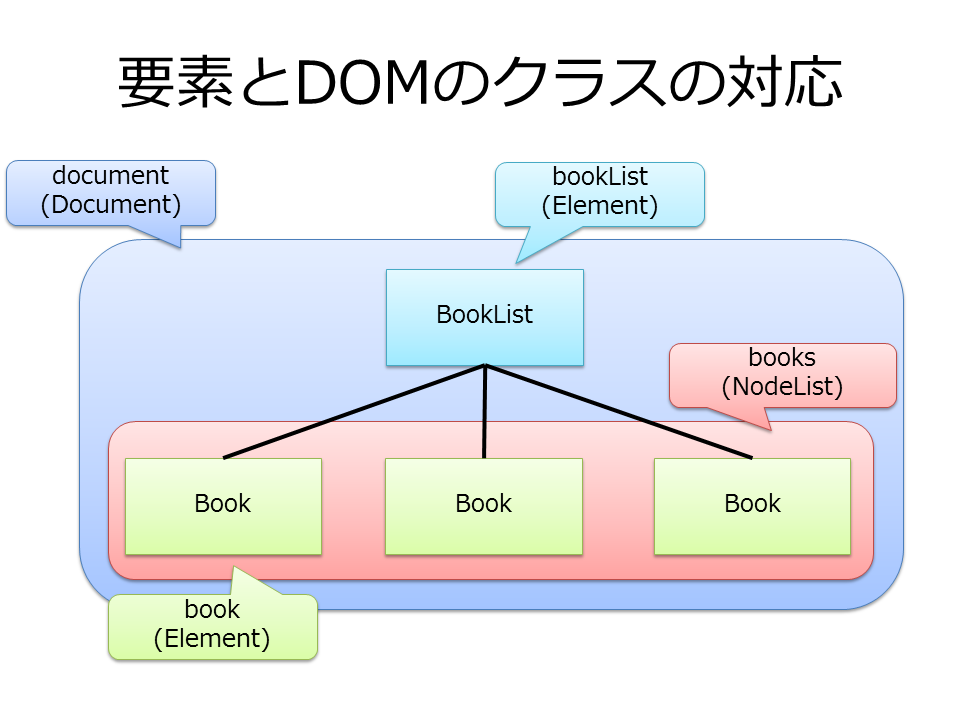
このように、DOMではXMLの一部分をDocumentからたどっていって必要なElementを探し出し、それらからテキストや属性値を取得したり、さらにその中のElementを検索して…を続けていくのです。
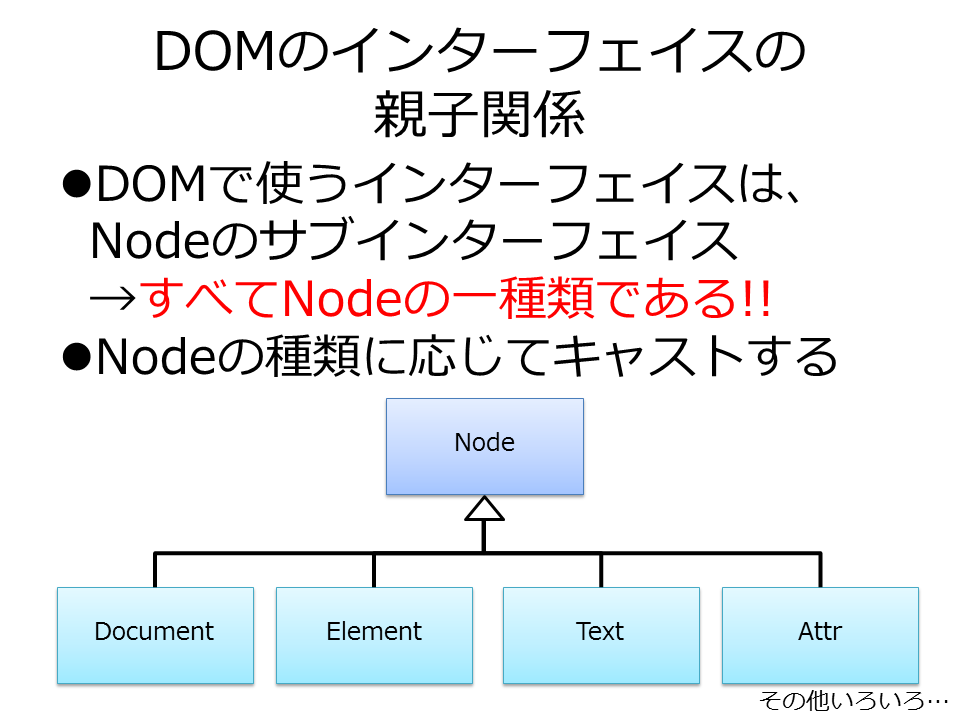
2-3.【参考】DOMで要素を探す方法いろいろ
DOMで目的とする要素を探すには、いくつかのやり方があります。基本は以下のどれかになります。今回の例では2.を使いました。
- XMLのツリー構造を上から順にたどっていく(getChildNodesなどでたどって、要素名を確認する)
- getElementsByTagNameで、タグ名を指定して探す
- getElementByIdで、要素のIDを指定して探す
- DOMのTraversalの機能を使ってたどっていく(TreeWalker、NodeIterator、NodeFilterなど) ※ここではDOMのTraversalの詳細は省きます。
2-3-1.【重要】getElementByIdはID属性を検索する
XML文書へのgetElementByIdは少し注意が必要です。XMLの構造を決めるDTDやXML Schemaで、ID属性として指定されている属性だけに有効です。決して、“id”や“ID”という属性名を探しているわけではないのです。
例えば、以下のDTDで属性isbnの後ろに“ID”がありますよね。これがID属性の指定で、これによりisbn属性がBook要素のID属性として機能します。XMLにDTDを紐付けていないとgetElementByIdでは検索できません。
<!DOCTYPE BookList [ <!ELEMENT BookList (Book+)> <!ELEMENT Book (#PCDATA)> <!ATTLIST Book isbn ID #REQUIRED author CDATA #REQUIRED title CDATA #REQUIRED > ]>
同じことをXML Schemaで書けば以下のようになります。途中にtype=”xsd:ID”というものがありますが、これでisbn属性がID属性であることを指定しているのです。
<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="BookList" type="BookListType" /> <xsd:complexType name="BookListType"> <xsd:sequence> <xsd:element type="BookType" name="Book" maxOccurs="unbounded" minOccurs="0" /> </xsd:sequence> </xsd:complexType> <xsd:complexType name="BookType"> <xsd:simpleContent> <xsd:extension base="xsd:string"> <xsd:attribute type="xsd:ID" name="isbn" use="required" /> <xsd:attribute type="xsd:string" name="author" use="required" /> <xsd:attribute type="xsd:string" name="title" use="required" /> </xsd:extension> </xsd:simpleContent> </xsd:complexType> </xsd:schema>
3.SAX(Simple API for XML Processing)で読み込む
SAX(Simple API for XML Processing)はXMLを読み込むためのAPIです。SAXの特徴は、イベント駆動と呼ばれるプログラムの仕方になることです。
SAX
javax.xml.stream (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/stream/package-summary.html
javax.xml.stream.events (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/stream/events/package-summary.html
javax.xml.stream.util (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/stream/util/package-summary.html
イベント駆動のイメージは、XMLを先頭から順番に読んでいった時の出来事、つまり要素が出現した、要素が終わった、テキストが出現したなどの「イベント」ごとに、あらかじめ決めてある処理が呼ばれるものです。
3-1.SAXでのXML読み込みプログラム
これも百聞は一見に如かず!! まずはSAXでXMLを読み込むプログラムをご覧ください。
import java.nio.file.Paths;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXSample extends DefaultHandler {
String isbn;
String title;
String author;
String text;
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 5. 何かの要素が始まった
if ("Book".equals(qName)) {
// 始まったのがBook要素なら、属性を読み取ってフィールドへ保存する
isbn = attributes.getValue("isbn");
author = attributes.getValue("author");
title = attributes.getValue("title");
}
}
public void characters(char[] ch, int start, int length) throws SAXException {
// 6. テキストが出現したなら、char配列をStringにしてフィールドへ保存する
text = new String(ch, start, length);
}
public void endElement(String uri, String localName, String qName) throws SAXException {
// 7. 何かの要素が終わった
if ("Book".equals(qName)) {
// 終わったのがBook要素なら、フィールドに保存したBook要素の情報を出力する
System.out.println("isbn = " + isbn);
System.out.println("author = " + author);
System.out.println("title = " + title);
System.out.println("text = " + text);
System.out.println();
}
}
public static void main(String[] args) throws Exception {
// 1. SAXParserFactoryを取得
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2. SAXParserを取得
SAXParser parser = factory.newSAXParser();
// 3. SAXのイベントハンドラを生成(このクラスのインスタンス)
SAXSample handler = new SAXSample();
// 4. SAXParserにXMLを読み込ませて、SAXのイベントハンドラに処理を行わせる
parser.parse(Paths.get("/bookList.xml").toFile(), handler);
}
}3-2.プログラムの簡単な解説
さて、DOMとはずいぶんプログラムが変わりました。Book要素を探していませんし、ループもありません。でも、これを実行するとDOMの場合と同じ出力になるのです…不思議ですね。
プログラムの考え方は、以下となります。先ほどお伝えしたとおり、XMLを先頭から読み取っていって、要素やテキストが出現するごとに、DefaultHandlerが持つメソッドのうち、決められたものが呼ばれるのです。

ですから、DOMとは違いXMLの構造を意識せずにすむので、プログラムは比較的簡単です。SAXの“Simple”はこれを意味しています。処理したい要素に到着するまで待って、到着したらやりたいことをするのです。
逆に、XMLの構造を強く意識したプログラムは、SAXは苦手です。今処理している要素の親要素や子要素が何かが、SAXでは直接わからないからです。ですので、ツリー構造を意識したプログラムは複雑になります。
3-3.【参考】SAXでのイベントの種類
SAXのイベントの発生タイミングをまとめました。詳しくは以下のJavadocか、SAX Projectのドキュメントを参照してください。DefaultHandlerは~Handlerを全て空で実装している、継承元として便利なクラスです。
ContentHandler (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/org/xml/sax/ContentHandler.html
DTDHandler (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/org/xml/sax/DTDHandler.html
EntityResolver (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/org/xml/sax/EntityResolver.html
ErrorHandler (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/org/xml/sax/ErrorHandler.html
DefaultHandler (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/org/xml/sax/helpers/DefaultHandler.html
ContentHandler
- startDocument:XML文書が始まった時
- endDocument:XML文書が終わった時
- startElement:要素が始まった時
- endElement:要素が終わった時
- startPrefixMapping:名前空間のマッピングが始まった時
- endPrefixMapping:名前空間のマッピングが終わった時
- characters:文字が出現した時
- ignorableWhitespace:無視できる空白文字が出現した時
- processingInstruction:処理命令(<? ~ ?>)が出現した時
- skippedEntity:処理に失敗したエンティティがあった時
- setDocumentLocator:読み取っているXMLの桁数・行数が変わった時
DTDHandler
- notationDecl:表記法宣言(<!NOTATION ~>)が出現した時
- unparsedEntityDecl:解析対象外エンティティ宣言が出現した時
EntityResolver
- resolveEntity:外部エンティティの解決が必要な時
ErrorHandler
- warning:XMLの処理中に警告が発生した時
- error:XMLの処理中にエラーが発生した時
- fatalError:XMLの処理中に復帰不可能なエラーが発生した時
4.StAX(Streaming API for XML)で読み込む
次はStAX(Streaming API for XML)です。これもDOMやSAXとは違うスタイルのプログラミングになります。StAXはイベント駆動なプログラミングスタイルの一種ですが、SAXとはイベントの取り扱い方が違います。
Streaming API for XML – ウィキペディア
https://ja.wikipedia.org/wiki/Streaming_API_for_XML
JSR 173 – JCP.org
StAXの特徴は以下のものです。
- Pull型である。イベントの種類をStAXのクラスに聞いて、必要な処理を自分で呼び出す。
- Iteratorパターンで実装する。Iterateする要素は、XMLを読む上で起きたイベントである。
- SAXよりも制限が緩い。SAXのように決まったクラス(DefaultHandler)やインターフェイス(ContentHandlerなど)を継承・実装しなくてもいい。
なお、StAXではXMLの読み込みにXMLStreamReaderとXMLEventReaderのどちらかを使います。これらの間でも、少しプログラミングの仕方が違うので、ここでは両方紹介します。
4-1.StAXでのXML読み込みプログラム(XMLStreamReaderを使う方法)
StAXのXMLStreamReaderでXMLを読み込むプログラムは、こんな感じになります。
import java.io.FileInputStream;
import java.nio.file.Paths;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamReader;
public class StAXSample {
public static void main(String[] args) throws Exception {
XMLStreamReader reader = null;
try {
// 1.XMLInputFactoryを取得する
XMLInputFactory factory = XMLInputFactory.newInstance();
// 2.XMLStreamReaderを生成し、XMLファイルを読み込ませる
reader = factory.createXMLStreamReader(new FileInputStream(Paths.get("/bookList.xml").toFile()));
String isbn = null;
String author = null;
String title = null;
StringBuilder text = new StringBuilder();
// 3.XMLStreamReaderにイベントがまだあるか聞いて、あるならループを継続
while (reader.hasNext()) {
// 4.次のイベントに突入!!
// nextの戻り値はイベント種類の数値で、XMLStreamConstantsで決められている
int eventType = reader.next();
switch (eventType) {
// 5.要素が始まったならSTART_ELEMENT
case XMLStreamConstants.START_ELEMENT:
// 今処理している要素がBookなら、属性を読み込む
if ("Book".equals(reader.getName().getLocalPart())) {
isbn = reader.getAttributeValue(null, "isbn");
author = reader.getAttributeValue(null, "author");
title = reader.getAttributeValue(null, "title");
text.setLength(0);
}
break;
// 6.テキストが出て来たならCHARACTERS
case XMLStreamConstants.CHARACTERS:
text.append(reader.getText());
break;
// 7.要素が終わったならEND_ELEMENT
case XMLStreamConstants.END_ELEMENT:
// 今処理している要素がBookなら、属性とテキストを出力する
if ("Book".equals(reader.getName().getLocalPart())) {
System.out.println("isbn = " + isbn);
System.out.println("title = " + title);
System.out.println("author = " + author);
System.out.println("text = " + text.toString());
System.out.println();
}
break;
}
}
} finally {
// 8.処理が終わったら、忘れずにXMLStreamReaderをcloseする
if (reader != null) {
reader.close();
}
}
}
}4-2.プログラムの簡単な解説(XMLStreamReader)
全体の雰囲気はSAXに似ています。でも、StAXでは起きたイベントが何かを自分で調べて、対応する処理を自分で書きます。一方、SAXでは起きたイベントごとに、イベントハンドラのメソッドが自動で呼び出されます。
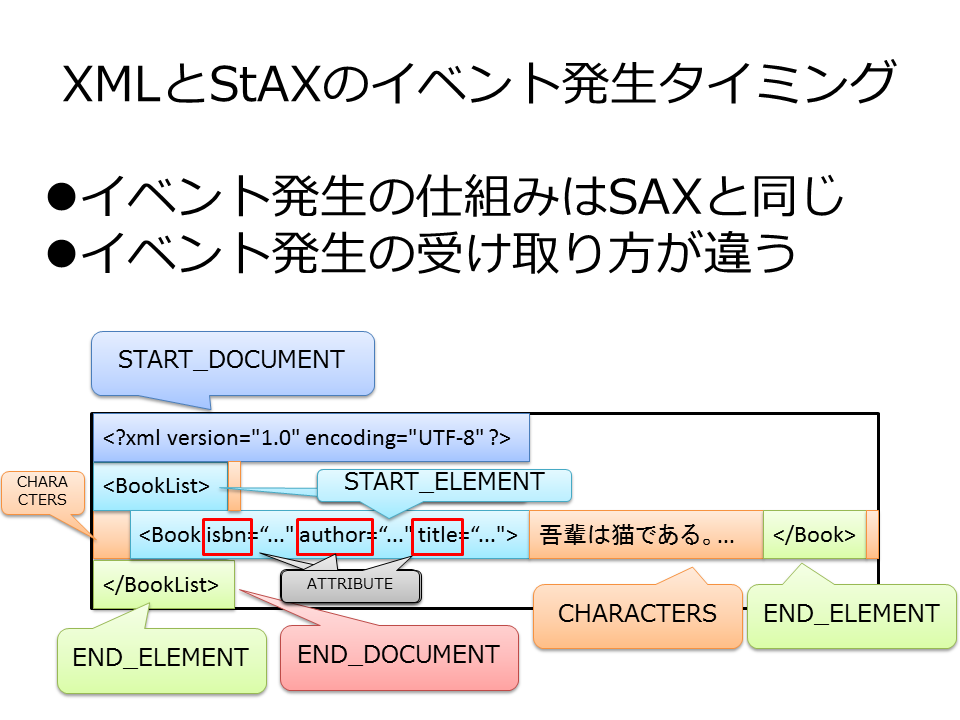
今、XMLのどこにいるかはXMLStreamReader自身が分かっています。まだ次のイベントがあるならhasNextはtrueを戻し、nextするとどのイベントかをXMLStreamConstantsにある数字で戻してくれます。
XMLStreamConstants (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/stream/XMLStreamConstants.html
そして、XMLStreamReaderのメソッドを呼べばXMLの情報を得られます。今いるのが要素ならタグ名が分かりますし、属性ならその値、テキストならその文字列などをXMLStreamReaderが教えてくれます。
XMLStreamReader (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/stream/XMLStreamReader.html
4-3.StAXでのXML読み込みプログラム(XMLEventReaderを使う方法)
StAXのもう一つのクラスXMLEventReaderでXMLを読み込むプログラムは、こんな感じになります。
import java.io.FileInputStream;
import java.nio.file.Paths;
import javax.xml.namespace.QName;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.events.Attribute;
import javax.xml.stream.events.StartElement;
import javax.xml.stream.events.XMLEvent;
public class StAXSample2 {
public static void main(String[] args) throws Exception {
XMLEventReader reader = null;
try {
XMLInputFactory factory = XMLInputFactory.newInstance();
reader = factory.createXMLEventReader(new FileInputStream(Paths.get("/bookList.xml").toFile()));
String qName = null;
String isbn = null;
String author = null;
String title = null;
String text = null;
QName isbnQname = new QName("isbn");
QName authorQname = new QName("author");
QName titleQname = new QName("title");
while (reader.hasNext()) {
XMLEvent event = reader.nextEvent();
if (event.isStartElement()) {
StartElement element = event.asStartElement();
qName = element.getName().getLocalPart();
if ("Book".equals(qName)) {
Attribute isbnAttr = element.getAttributeByName(isbnQname);
Attribute titleAttr = element.getAttributeByName(titleQname);
Attribute authorAttr = element.getAttributeByName(authorQname);
isbn = isbnAttr.getValue();
title = titleAttr.getValue();
author = authorAttr.getValue();
}
} else if (event.isCharacters()) {
if ("Book".equals(qName)) {
text = event.asCharacters().getData();
}
} else if (event.isEndElement()) {
if ("Book".equals(qName)) {
System.out.println("isbn = " + isbn);
System.out.println("title = " + title);
System.out.println("author = " + author);
System.out.println("text = " + text.toString());
System.out.println();
}
qName = null;
}
}
} finally {
if (reader != null) {
reader.close();
}
}
}
}4-4.プログラムの簡単な解説(XMLEventReader)
プログラムの流れはXMLEventReaderでも、XMLStreamReaderと同じです…というか、わざと同じにしました。XMLStreamReaderの例ではswitch文で、こちらはif文です。でも、それは本質的な違いではないのです。
XMLEventReaderでは、イベントがXMLEventにカプセル化されます。これがXMLStreamReaderとの違いです。XMLEventを使えば、イベントへの処理を別のメソッドやクラスに行わせるのが簡単・安全になるのです。
XMLEventReader (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/stream/XMLEventReader.html
XMLEvent (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/stream/events/XMLEvent.html
なぜかというと、XMLEventには次のイベントに進めるメソッドがないので、他のクラスやメソッドにXMLEventを渡しても、XMLの読み取りを安全に進められます。さらに、イベントハンドラを自分でも作れるのです。
XMLStreamReaderはhasNextやnextができるので、XMLStreamReaderを別のクラスやメソッドに渡すと、こっそり次のイベントへ進められます。それが役に立つこともありますが、バグの原因にもなりかねません。
4-4-1.【発展】XMLEventを使ったイベントハンドラの例
SAXでのContentHandlerのようなクラスをXMLEventで簡単に作ってみると、以下となります。こういうものを自分の都合に合わせて自由に作れるのが、XMLEventReaderやXMLEventのいいところです。
import java.io.FileInputStream;
import java.nio.file.Path;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.events.Characters;
import javax.xml.stream.events.EndElement;
import javax.xml.stream.events.StartElement;
import javax.xml.stream.events.XMLEvent;
abstract class MyContentHandler {
final void read(Path xml) throws Exception {
XMLEventReader reader = null;
try {
XMLInputFactory factory = XMLInputFactory.newInstance();
reader = factory.createXMLEventReader(new FileInputStream(xml.toFile()));
while (reader.hasNext()) {
XMLEvent event = reader.nextEvent();
if (event.isStartElement()) {
startElement(event.asStartElement());
} else if (event.isCharacters()) {
characters(event.asCharacters());
} else if (event.isEndElement()) {
endElement(event.asEndElement());
}
}
} finally {
if (reader != null) {
reader.close();
}
}
}
// 要素開始時に呼び出される抽象メソッド
abstract void startElement(StartElement element);
// テキスト出現時に呼び出される抽象メソッド
abstract void characters(Characters characters);
// 要素終了時に呼び出される抽象メソッド
abstract void endElement(EndElement element);
}import java.nio.file.Paths;
import javax.xml.stream.events.Characters;
import javax.xml.stream.events.EndElement;
import javax.xml.stream.events.StartElement;
class MyContentHandlerImpl extends MyContentHandler {
// 要素開始時の抽象メソッドの実装
void startElement(StartElement element) {
System.out.println(element.getName().getLocalPart());
}
// テキスト出現時の抽象メソッドの実装
void characters(Characters characters) {
System.out.println(characters.getData());
}
// 要素終了時の抽象メソッドの実装
void endElement(EndElement element) {
System.out.println(element.getName().getLocalPart());
}
public static void main(String[] args) throws Exception {
new MyContentHandlerImpl().read(Paths.get("/bookList.xml"));
}
}5.XPath(XML Path Language)で読み込む
XPathは他のAPIとは大分違います。XPathはXMLの検索方法の一つで、データベースへのSQLに似ています。検索条件をXPathの構文で書いてXMLに問い合わせると、条件を満たす要素やテキストが簡単に得られます。
XML Path Language
https://ja.wikipedia.org/wiki/XML_Path_Language
XML Path Language (XPath)
https://www.w3.org/TR/1999/REC-xpath-19991116/
javax.xml.xpath (Java SE 11 & JDK 11)
https://docs.oracle.com/javase/jp/11/docs/api/java.xml/javax/xml/xpath/package-summary.html
DOMでは要素を順番にたどったり、タグ名やID属性での検索もできます。でも、プログラムの行数は増えてしまいがちです。SAXやStAXはイベント駆動なので、要素の親子関係を意識した処理はちょっと苦手です。
でも、XPathではそれらをすべてクリアできます。欲しい情報をダイレクトに、かつ短いプログラム行数で得られます。要素の親子関係で検索できますし、属性値が何か、テキストに何かを含む、なども指定できるのです!!
5-1.XPathでのXML読み込みプログラム
ではさっそくXPathでXMLを読み込んでみましょう。
import java.io.FileInputStream;
import java.nio.file.Paths;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
public class XPathSample {
public static void main(String[] args) throws Exception {
// 1.Documentを作るまでの流れはDOMと同じ
FileInputStream is = new FileInputStream(Paths.get("/bookList.xml").toFile());
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(is);
// 2.XPathの処理を実行するXPathのインスタンスを取得する
XPath xpath = XPathFactory.newInstance().newXPath();
// 3.XPathでの検索条件を作る
XPathExpression expr = xpath.compile("/BookList/Book");
// 4.DocumentをXPathで検索して、結果をDOMのNodeListで受け取る
NodeList nodeList = (NodeList) expr.evaluate(document, XPathConstants.NODESET);
// 5.XPathでの検索結果を持っているNodeListの内容でループ
for (int i = 0; i < nodeList.getLength(); i++) {
// 6.要素を検索しているのでNodeの実体はElement。キャストして使う。
Element element = (Element) nodeList.item(i);
// 7.Elementから必要な情報を取得して出力する
System.out.println("isbn = " + element.getAttribute("isbn"));
System.out.println("title = " + element.getAttribute("title"));
System.out.println("author = " + element.getAttribute("author"));
System.out.println("text = " + element.getTextContent());
System.out.println();
}
}
}5-2.プログラムの簡単な解説
XPathは検索の仕組みなので、XPathでは検索条件を指定するだけで、検索結果はDOMのクラスになります。ここでは検索結果はNodeListで戻すように、検索をする時の引数で指定しています。
キモは、3.でのXPathでの検索条件です。文字列で“/BookList/Book”とありますよね。これは「ルート要素のBookList要素の直下にあるBook要素を全て取得する」を意味しているのです。
4.でXMLから検索すると、XPathでの検索条件にヒットしたモノが戻ります。ですから、DOMでの検索やSAX・StAXのプログラムの作り方とはかなり違いますよね。これはSQLで検索して結果を得るのと似ています。
5-3.【参考】XPathでのいろいろな検索の仕方
先程の例では要素のタグ名で検索しました。もちろんXPathではもっと別の検索条件も使えます。属性の値、テキストの部分一致などです。検索結果としても、要素だけではなく属性の値や、テキストを指定できます。
例えば、以下のようにもできるのです。欲しいものをXPathの検索条件として指定すれば、それが得られます。なんとなく雰囲気が分かるかと思います。多分、[]が抽出条件で、@が属性かなぁ…という感じがしますよね。
例1: ISBNが”ISBN978-4-1234-0001-5″のBook要素を取得する
XPathExpression expr2 = xpath.compile("//Book[@isbn = 'ISBN978-4-1234-0001-5']");
Element element2 = (Element) expr2.evaluate(document, XPathConstants.NODE);
System.out.println("title = " + element2.getAttribute("title"));
例2: テキストに”cat”を含むBook要素を取得する
XPathExpression expr3 = xpath.compile("//Book[contains(text(), 'cat')]");
Element element3 = (Element) expr3.evaluate(document, XPathConstants.NODE);
System.out.println("title = " + element3.getAttribute("title"));
例3: title属性が”The Cats of Ulthar”であるBook要素のauthor属性の値を取得する
XPathExpression expr4 = xpath.compile("//Book[@title = 'The Cats of Ulthar']/@author");
String author = (String) expr4.evaluate(document, XPathConstants.STRING);
System.out.println("author = " + author);
例4: title属性が”The Cats of Ulthar”であるBook要素のテキストを取得する
XPathExpression expr5 = xpath.compile("//Book[@title = 'The Cats of Ulthar']/text()");
String text = (String) expr5.evaluate(document, XPathConstants.STRING);
System.out.println("text = " + text);XPathで出来ることは、実はまだまだこんなものではありません。もし興味があれば、XPathをもっと深く学んでみるといいでしょう。そして、XPathが分かれば、その関連仕様であるXQueryの理解も見えてきますよ。
6.【参考】JAXB(Java Architecture for XML Binding)で読み込む
過去のJava SEでは、JAXB(Java API for XML Binding)というAPIも使えました。このAPIは今もありますが、Java SE 11からは削除され、エンタープライズ向けのJava EE(現Jakarta EE)の機能の位置付けになりました。
JAXBの特徴は、XMLの構造とJavaのクラスを直接紐付けることです。XMLと紐付けたクラスを作っておけば、JAXBのクラスのメソッドを呼び出すだけで、XMLの内容が反映されたクラスのインスタンスが得られます。
つまり、DOMやSAXやStAXのように、XMLをプログラム上であれこれいじり回す必要はないのです。その代りに、アノテーションなどでXMLの構造とクラスを紐付けておくという、事前作業が必要になります。
6-1.JAXBでのXML読み込みプログラム
この例のXMLでは、BookListとBookという二つの要素があります。ですので、今回のJAXBの例では対応する二つのクラスをXMLの構造に合わせて作ってみます。
import java.util.List;
import javax.xml.bind.annotation.XmlAccessType;
import javax.xml.bind.annotation.XmlAccessorType;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
@XmlRootElement(name = "BookList")
public class BookList {
@XmlElement(name = "Book")
List<Book> books;
}import javax.xml.bind.annotation.XmlAttribute;
import javax.xml.bind.annotation.XmlRootElement;
import javax.xml.bind.annotation.XmlValue;
@XmlRootElement(name = "Book")
public class Book {
@XmlAttribute
String isbn;
@XmlAttribute
String author;
@XmlAttribute
String title;
@XmlValue
String text;
public String toString() {
return new StringBuilder()
.append("isbn = ").append(isbn).append('\n')
.append("author = ").append(author).append('\n')
.append("title = ").append(title).append('\n')
.append("text = ").append(text).append("\n")
.toString();
}
}import java.nio.file.Paths;
import javax.xml.bind.JAXB;
public class JAXBSample {
public static void main(String[] args) {
BookList bookList = JAXB.unmarshal(Paths.get("/bookList.xml").toFile(), BookList.class);
bookList.books.forEach(System.out::println);
}
}6-2.プログラムの簡単な解説
BookListは、フィールドとしてBookのListであるbooksを持っているだけのクラスです。booksへ、XmlElementでこのListの内容をBookという要素として出力するように指定しています。
Bookでは、各フィールドを要素の属性として出力するよう、XmlAttributeで指定しています。属性名はフィールドの変数名が使われます。さらに、textを要素のテキストとして出力するようXmlValueで指定しています。
そして、JAXB.unmarshalの引数にXMLとクラスを指定すれば、Javaのクラスのインスタンスにできます。なお、この例ではXMLから読んでいますが、逆にインスタンスをXMLにすることも、以下のようにできるのです。
import java.nio.file.Paths;
import java.util.ArrayList;
import javax.xml.bind.JAXB;
public class JAXBSample2 {
public static void main(String[] args) throws Exception {
// 1.吾輩は猫である、をBookとして生成
Book wagahai = new Book();
wagahai.isbn = "ISBN978-4-1234-0001-5";
wagahai.author = "夏目漱石";
wagahai.title = "吾輩は猫である";
wagahai.text = "吾輩は猫である。名前はまだない。どこで生れたかとんと見当がつかぬ。";
// 2.The Cats of Ulthar、をBookとして生成
Book ulthal = new Book();
ulthal.isbn = "ISBN978-4-1234-0002-2";
ulthal.author = "H. P. Lovecraft";
ulthal.title = "The Cats of Ulthar";
ulthal.text = "It is said that in Ulthar, which lies beyond the river Skai, no man may kill a cat;";
// 3.Lebensansichten des Katers Murr、をBookとして生成
Book murr = new Book();
murr.isbn = "ISBN978-4-1234-0003-9";
murr.author = "E. T. A. Hoffmann";
murr.title = "Lebensansichten des Katers Murr";
murr.text = "Es ist doch etwas Schönes, Herrliches, Erhabenes um das Leben!";
// 4.BookListを生成して、それぞれのBookを格納する
BookList bookList = new BookList();
bookList.books = new ArrayList<>();
bookList.books.add(wagahai);
bookList.books.add(ulthal);
bookList.books.add(murr);
// 5.JAXBを使って、インスタンスの内容をXMLにする!!
JAXB.marshal(bookList, Paths.get("Z:/marshal.xml").toFile());
}
}6-3.Java SE 9以降でJAXBを使う方法
Java SE 9/10ではJAXB関連のクラスがあるモジュールはまだありますので、JAXBのモジュールをaddすれば使えます。例えば、javaコマンドへの引数に –add-modules java.xml.bind あるいは –add-modules java.se.ee を追加すれば一応は使えます。
ですが、Java SE 11からはJAXB関連のクラスがあるモジュール自体が含まれなくなってしまいましたので、このaddする方法はもう使えません。どこかから、JAXBで使うクラスを持ってこなければならないのです。
JAXBを使うためのAPIや実行クラスは、例えばMavenを使っている場合は、pom.xmlへ以下の依存先ライブラリを追加することで使えるようになります(バージョンは2019/4時点での最新のものです)。
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.4.0-b180830.0359</version>
</dependency>
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.4.0-b180830.0438</version>
</dependency>
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.3.0.1</version>
</dependency>7.【参考】普通のファイル読み込み+文字列処理で読み込む
今までご紹介してきたXML用のAPIを使わなくても、XMLを読み込むことはできます。XMLと言えども単なる文字列の集まりですから、できることを割り切ってしまえば、文字列処理の範囲で対応できなくもないからです。
XMLの構造が分かっていて、かつ書かれ方が統一されていれば、以下のようにも作れます。ある意味で、処理内容はとても分かりやすいですし、XMLの解析は文字列処理の勉強をするのにちょうどいいテーマでもあります。
7-1.普通のファイル読み込み+文字列処理でのXML読み込みプログラム
ここでは、普通のファイル読み込みと正規表現を使ったプログラムの簡単な例をご紹介します。XMLの仕様からしてみれば機能が足りないところだらけですが、実用上ではこんなものでも十分使えるものだったりします。
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringSample {
public static void main(String[] args) throws IOException {
// 1. Book要素全体とマッチングさせるための正規表現を生成する
Pattern elemPattern = Pattern.compile("<Book (?<attrs>.+)?>(?<text>.+?)</Book>");
// 2. Book要素内の属性一覧とマッチングさせるための正規表現を生成する
Pattern attrPattern = Pattern.compile("(?<attrname>isbn|author|title)=\"(?<attrvalue>.+?)\"");
// 3. Files.readAllLinesを使って、XMLを一気に読み込んで、ループをする
Files.readAllLines(Paths.get("/bookList.xml")).forEach(s -> {
// 4. Book要素とマッチングをして、
Matcher elemMatcher = elemPattern.matcher(s);
// 5. Book要素の行であれば、
if (elemMatcher.find()) {
// 6. Book要素の属性部分を取り出して、さらにマッチング
String attrs = elemMatcher.group("attrs");
Matcher attrMatcher = attrPattern.matcher(attrs);
// 7. マッチした属性部分の情報をすべて出力する
while (attrMatcher.find()) {
System.out.println(attrMatcher.group("attrname") + " = " + attrMatcher.group("attrvalue"));
}
// 8. テキスト部分は最初のマッチングの結果から取ってくる
System.out.println("text = " + elemMatcher.group("text"));
System.out.println();
}
});
}
}7-2.プログラムの簡単な解説
このプログラムでは、XMLファイルの行をすべて読み込んで、行単位に処理をしています。行の文字列をsubstringしても別にいいのですが、正規表現を使う方がプログラミングが楽ですし、短くもなります。
まず、Book要素の行かどうかを、属性部分とテキスト部分を抜き出す正規表現で確認しています。マッチさせるのと同時に、マッチした部分を後から抜き出せるよう、マッチ部分に名前を付けています(attrとtext)。
さらに、Book要素だと思われる行なら、出力したい属性を正規表現で抜き出します。こちらも属性名と属性値のマッチ部分に名前を付けて(attrnameとattrvalue)、マッチした部分すべてをループして取り出しています。
正規表現でのポイントは、マッチ部分に名前を付けていること(?<名前>)と、マッチ方法を最短一致(.+?)としていることです。Javaの正規表現は通常は最長一致なので、余計なものまでついてくるからですね。
8.まとめ
この記事では、Java SEで使えるXML読み込みの4つの方法を、サンプルを交えてお伝えしました。その4つの方法とは、DOM、SAX、StAX、XPathです。その他にも、JAXBとXMLを直接解釈する方法もご紹介しました。
同じXMLを読んで同じ出力をするだけでも、やり方が大きく違うとお分かりいただけたかと思います。ですので、プログラムでやりたいことにピッタリのやり方を選べるよう、それぞれ使い方を学んでおくといいでしょう。
また、Javaの標準APIの他にも、以下のような外部ライブラリが使えます。DOM、SAX、StAX、XPathなどのいいとこ取りをしているようなものもありますので、興味があれば使ってみてもいいと思いますよ。
- JDOM(http://www.jdom.org/)
- DOM4J(https://dom4j.github.io/)
- XOM(http://www.xom.nu/)

コメント