
Javaのsubstringとは?部分文字列取得の基本「String.substring()」の使い方

Javaでの部分文字列の取得はString.substring()で行うのが基本です。
String.substring()の使い方を知ることは、実用的なプログラムを作れるようになるための第一歩です。部分文字列の取得は、実務でのプログラミングでも頻繁に行います。
この記事ではString.substring()や、関連するString.indexOf()について初心者向けに解説しますので、ぜひ使い方を覚えて行ってください。

目次
1.【Java】String.substring()の使い方
1-1.Stringのインデックスとは文字単位の位置
ここでString.substring()を使うために必要な、Stringのインデックスの考え方をまず覚えましょう。
Stringのインデックスとは、文字列中に含まれる文字に順番に割り当てられた数字です。
文字列の最初の文字がインデックス 0 で、順番に+1されます。これは配列の添え字と同じルールです。ですので、最後の文字のインデックスは、String.length()より1少ない数になります。
String str = "あいうえお";
// 文字列をインデックスと一緒に表示
for (int i = 0; i < str.length(); i++) {
System.out.println(String.format("strのインデックス %d は %s です。", i, str.charAt(i)));
}
※出力結果:
strのインデックス 0 は あ です。
strのインデックス 1 は い です。
strのインデックス 2 は う です。
strのインデックス 3 は え です。
strのインデックス 4 は お です。
なお、JavaではStringを使う場合は文字数でインデックスを指定します。他のプログラミング言語でShift_JISなどを扱う時とは違い、各文字のbyte数は意識しなくてもよいので、いわゆる全角・半角の文字種判断結果による調整も不要です。
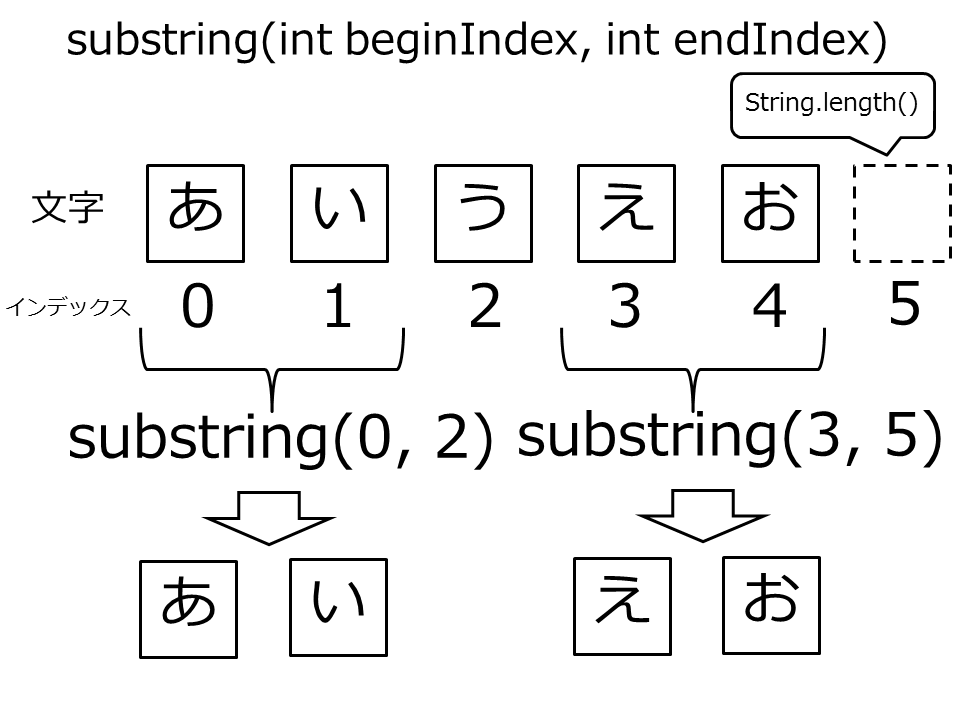
1-2.指定範囲の部分文字列の取得
Stringからの文字列の部分文字列の取得には、String.substring(int, int)を使います。2つ目の引数は、切り出す文字数ではなくインデックスですので、他のプログラミング言語やSQLなどの文法と混同しないようにしましょう。さらに、引数の説明文の「含む」「含まない」という表現にも注意しましょう。
// substring(int, int)のメソッド定義 public String substring(int beginIndex, int endIndex) beginIndex - 開始インデックス(この値を含む) endIndex - 終了インデックス(この値を含まない)
String str = "あいうえお"; String str2 = str.substring(0, 2); // インデックス0(=1文字目)から、インデックス2の前(2文字目)まで切り出す System.out.println(str2); // → "あい" String str3 = str.substring(3, 5); // インデックス3(=4文字目)から、インデックス5の前(5文字目)まで切り出す System.out.println(str3); // → "えお"
文字列中の文字数を超えた範囲のインデックスを指定すると、例外(IndexOutOfBoundsException)が発生します。例外発生時は開始・終了インデックスが、指定できる範囲内か確認しましょう。
String str = "あいうえお"; // "あいうえお"の場合は、インデックスは最大で4 String str4 = str.substring(5, 1); // 開始インデックスは0~4まで指定できる String str5 = str.substring(0, 6); // 終了インデックスは0~5まで指定できる
1-3.指定インデックスから後ろの部分文字列の取得
あるインデックスから後ろの文字列を全て部分文字列として取得する場合は、String.substring(int)を使います。String.substring(int, int)でもできますが、こちらの方が簡単です。
// substring(int)のメソッド定義 public String substring(int beginIndex) beginIndex - 開始インデックス(この値を含む)
使用例は以下のとおりです。
String str = "あいうえお"; String str6 = str.substring(2); // インデックス2(3文字目)から最後まで切り出す System.out.println(str6); // → "うえお" String str7 = str.substring(0); // インデックス0(1文字目)から全て→事実上同じ文字列 System.out.println(str7); // → "あいうえお"
1-4.部分文字列の比較にはString.equals()を使う
JavaのStringの特徴は不変(Immutable)であることです。不変とは、Stringの個々のインスタンスが保持している値は、何をしても変わらないということです。
ですので、String.substring()を実行した後でも、部分文字列の取得元のStringで保持している値は何も変わっていません。String.substring()は、部分文字列の新しいStringのインスタンスを戻すだけだからです。
String str = "あいうえお"; String str8 = str.substring(1, 3); System.out.println(str); // → "あいうえお" 部分文字列の取得元のStringは何も変わっていない System.out.println(str8); // → "いう"
String.substring()を実行すると都度異なるStringのインスタンスが生成されますので、部分文字列の比較にインスタンスの同値性を比較する == を使うと、通常想定する結果が得られません。Stringの比較にはequalsを使いましょう。
tring str = "あいうえお"; String str9 = str.substring(2, 4); String str10 = str.substring(2, 4); System.out.println(str9); // "うえ" System.out.println(str10); // "うえ" System.out.println(str9 == str10); // false、保持している文字は等しいが、インスタンスが違うため System.out.println(str9.equals(str10)); // true、equalsはStringの文字単位で同じかをチェックするため
2.【応用】String.indexOf()との組み合わせ
String.substring()は切り出すインデックスの具体的な数値が必要です。ですので、例えば「文字列中にあるはずの文字から始まるインデックスから、部分文字列を得たい」という場合は、インデックスを取得するメソッドと組み合わせる必要があります。
インデックスを取得する基本はString.indexOf()です。String.indexOf()は対象のStrig内から文字あるいは文字列の一番最初のインデックスを戻します。ですので、これを開始/終了インデックスの値として使えます。
public int indexOf(int ch) ch - 文字(Unicodeコード・ポイント) public int indexOf(String str) str - 検索対象の部分文字列
例えば、以下のように組み合わせて使います。
String str = "あいうえお"; char c = 'う'; int beginIndex1 = str.indexOf(c); // → 'う'はインデックス 2 から始まる String str11 = str.substring(beginIndex); // substring(2) System.out.println(str11); // → "うえお" String subStr = "うえ"; int beginIndex2 = str.indexOf(subStr); // → "うえ"はインデックス 2 から始まる String str12 = str.substring(beginIndex2); // substring(2) System.out.println(str12); // → "うえお"
なお、String.indexOf()は文字あるいは文字列がString中に存在しない場合は-1を戻すので、String.substring()を実行する/しないの判断にも使えます。
String s2 = "か";
int beginIndex3 = str.indexOf(s2);
if (beginIndex3 != -1) {
String str13 = str.substring(beginIndex3);
System.out.println(str12);
} else {
System.out.println(s2 + "は含まれていません");
}String.indexOf()に関連するメソッドには以下のものがありますので、用途に応じて使い分けましょう。詳細はJava標準APIのドキュメントを参照してください。
// 検索を始める開始インデックスを指定できるもの public int indexOf(int ch, int fromIndex) public int indexOf(String str, int fromIndex) // 文字列の最後から検索するもの public int lastIndexOf(int ch) public int lastIndexOf(String str) // 文字列の最後から検索するが、検索を始める開始インデックスを指定できるもの public int lastIndexOf(int ch, int fromIndex) public int lastIndexOf(String str, int fromIndex)
3.【応用】String.substring()の活用例
3-1.ファイル拡張子、ファイル名部分の取得
String.substring()とString.lastIndexOf()の例として、ファイルの拡張子を得る際に使えます。拡張子を除く部分が必要な場合も同じ考え方です。
String fileName = "FILE.NAME.txt";
int endIndex = fileName.lastIndexOf('.'); // 最後の'.'のインデックスを検索
String extName = fileName.substring(endIndex + 1); // → "txt"、一番最後の'.'から後ろの文字列を全て取得
String baseName = fileName.substring(0, endIndex); // → "FILE.NAME"、先頭から一番最後の'.'の前までの部分文字列ファイルのパスからファイル名だけ抜き出したい場合も考え方は同じです。区切り文字を変えるだけですね。
String pathName = "/A/B/FILE.NAME.txt";
int endIndex = pathName.lastIndexOf('/'); // 最後の'/'のインデックスを検索
String fileName = pathName.substring(endIndex + 1); // → "FILE.NAME.txt"3-2.年月日・日時文字列の分解
年月日などの文字列をString.substrnig()で分解することも良く行います。
実務では正規表現でのパターンマッチングや、SimpleDateFormat/DateTimeFormatterなどでの解析も使いますが、文字列の書式が固定ならString.substring()の方が記述は簡単です。それに、単純な処理速度ならString.substring()がほぼ最速です。
String ymd = "20181017"; // YYYYMMDD形式 String year = ymd.substring(0, 4); // → 2018 String month = ymd.substring(4, 6); // → 10 String day = ymd.substring(6, 8); // → 17
String ymdhms = "20181017123456"; // YYYYMMDDHHMMSS形式 String year = ymd.substring(0, 4); // → 2018 String month = ymd.substring(4, 6); // → 10 String day = ymd.substring(6, 8); // → 17 String hour = ymd.substring(8, 10); // → 12 String min = ymd.substring(10, 12); // → 34 String sec = ymd.substring(12, 14); // → 56
String ymd = "2018-10-17"; // YYYY-MM-DD(ISO 8601拡張形式の日付)、区切りが'/'でも同じ String year = ymd.substring(0, 4); String month = ymd.substring(5, 7); String day = ymd.substring(7, 9);
String ymdhms = "2018/10/17 12:34:56"; // 日本では良く見かける書式 String year = ymdhms.substring(0, 4); // → 2018 String month = ymdhms.substring(5, 7); // → 10 String day = ymdhms.substring(8, 10); // → 17 String hour = ymdhms.substring(11, 13); // → 12 String min = ymdhms.substring(14, 16); // → 34 String sec = ymdhms.substring(17, 19); // → 56
String ymdhms = "2018-10-17T12:34:56+09:00"; // ISO 8601拡張形式の日時 String year = ymdhms.substring(0, 4); // → 2018 String month = ymdhms.substring(5, 7); // → 10 String day = ymdhms.substring(8, 10); // → 17 String hour = ymdhms.substring(11, 13); // → 12 String min = ymdhms.substring(14, 16); // → 34 String sec = ymdhms.substring(17, 19); // → 56 String timezone = ymdhms.substring(19); // → +09:00
3-3.CSVの分解
CSV(comma-separated values)などの、特定の区切り文字で連結した文字列から、各要素を抜き出す時にもString.substring()は使えます。簡単に行うならString.split()でいいのですが、区切り文字が“”で囲まれている場合など単純に処理出来ない場合もあるので、これをベースに拡張したりします。
String csvStr = "A,あいうえお,,C,1234";
List<String> csvElements = new ArrayList<>();
int beginIndex = 0;
while (true) {
int endIndex = csvStr.indexOf(',', beginIndex);
if (endIndex == -1) {
csvElements.add(csvStr.substring(beginIndex));
break;
} else {
csvElements.add(csvStr.substring(beginIndex, endIndex));
beginIndex = endIndex + 1;
}
}
System.out.println(csvElements); // → [A, あいうえお, , C, 1234]3-4.全角空白対応版trim
String.trim()は文字列の前後の空白(※)を削除しますが、日本語を扱う場合は、いわゆる全角空白も削除したい場合があります。その場合には、例えば以下のようなコードとなります。これはString.trim()のソースコードを一部変更したものです。
※正確には空白よりもコードポイントが小さい文字、詳細はAPIドキュメントを参照
String str = " あ い う え お "; // 全角空白が混ざっている
char[] val = str.toCharArray();
int len = val.length;
int st = 0;
while ((st < len) && (val[st] <= ' ' || val[st] == ' ')) {
st++;
}
while ((st < len) && (val[len - 1] <= ' ' || val[len - 1] == ' ')) {
len--;
}
String trimStr = ((st > 0) || (len < val.length)) ? str.substring(st, len) : str;
System.out.println("[" + trimStr + "]"); // → [あ い う え お] 前後の空白が削除された4.まとめ
Javaで部分文字列を取得するにはString.substring()を使います。String.substring()には範囲を指定するものと、最後まで指定するものの二種類がありますので、用途に応じて使い分けましょう。String中の文字のインデックスを取得するには、String.indexOf()やlastIndexOf()を使いましょう。
なお、この記事の内容はあくまで基本です。実務、特に入力文字列を制限しづらいWEB環境で使う際は、Unicodeのサロゲートペアや文字の合成・正規化の知識が必要になることがあります。もし想定どおりに部分文字列が取得できない場合は、これらのキーワードに関する知識も適宜学んでいきましょう。
コメント